
- While making the Gemini 1.5 Pro model generally available to all users, Google has also released API access for the promising model, as part of a public preview.
- You can use the model to input both texts and images and get output in texts.
- The API access is currently free to use until May 1, 2024.
Google recently concluded its Cloud Next 2024 event where the search giant made Gemini 1.5 Pro available to all users, as part of a public preview. And with that, it also opened API access to the Gemini 1.5 Pro model for all users. Earlier, Google released API access for Gemini 1.0 Pro but developers were waiting for this highly-promising model. Currently, the API is free to use and will remain so until May 1, 2024. So if you want to access and use the Gemini 1.5 Pro API key to evaluate the model, follow our guide below.
Get API Key For Gemini 1.5 Pro
- Head over to aistudio.google.com/app/apikey (visit) and sign in with your Google account.
- Click on “Create API key” and select one of the projects.

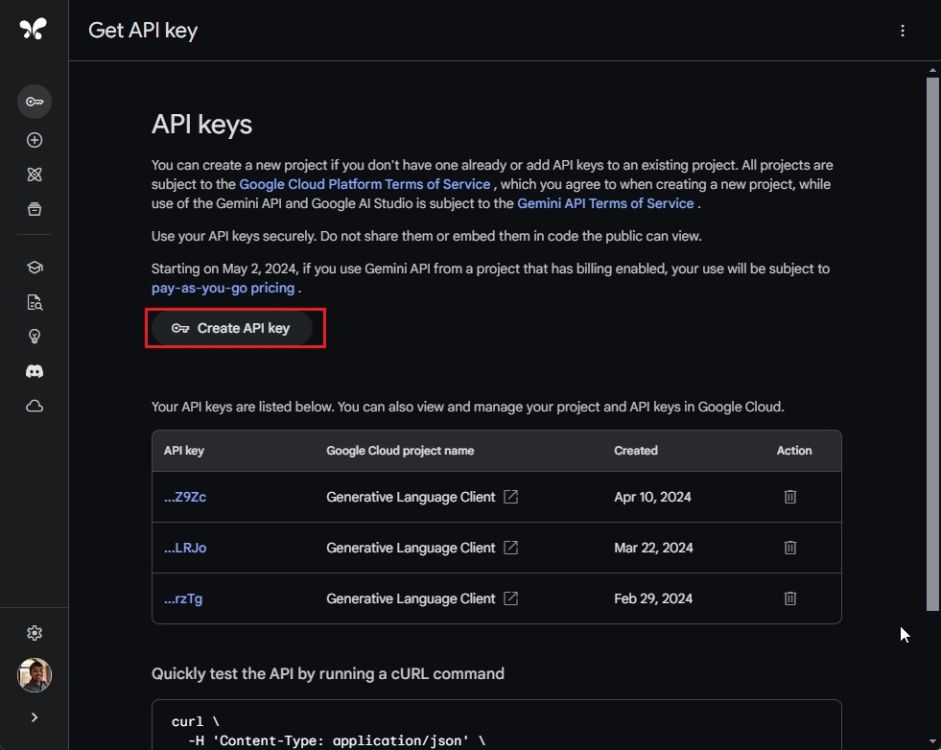
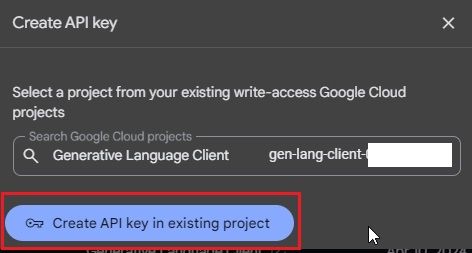
- Now, click on “Create API key in existing project“.

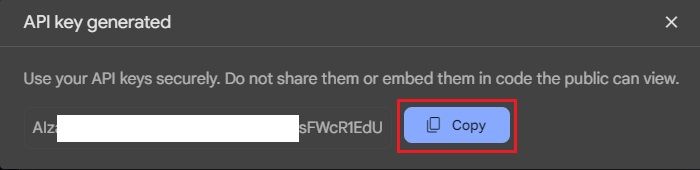
- And there you go! The Gemini 1.5 Pro API key will be generated right away. Copy and store it securely.

How to Use Gemini 1.5 Pro API Key
I am going to show some examples in Python on how to use the Gemini 1.5 Pro API key for both text and image examples. Here are the steps to follow.
- First of all, make sure you have installed Python along with Pip on your computer.
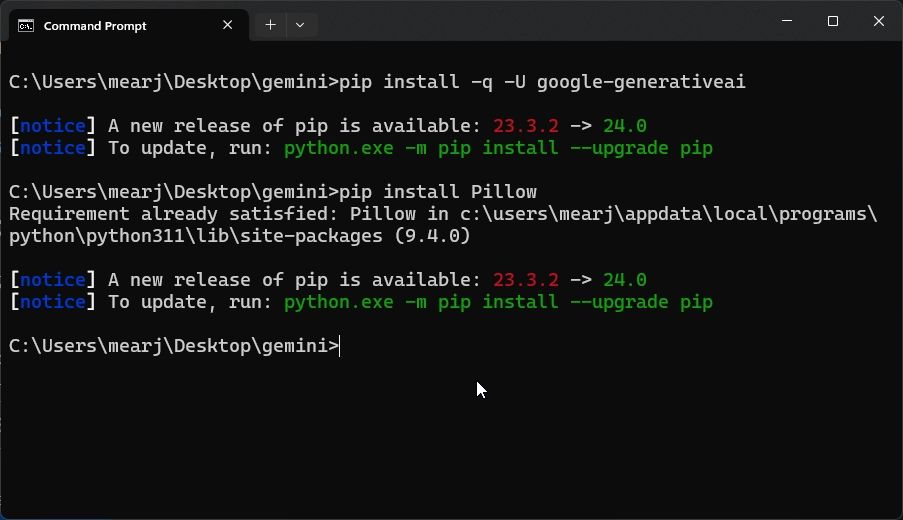
- After that, fire up the Terminal and run the below commands to install Gemini’s dependencies and Pillow to handle images.
pip install -q -U google-generativeai pip install Pillow

- Once you have done that, open a code editor of your choice like Notepad++ or Sublime. You can also open Visual Studio Code for a better IDE environment.
- Next, copy and paste the below code into your code editor.
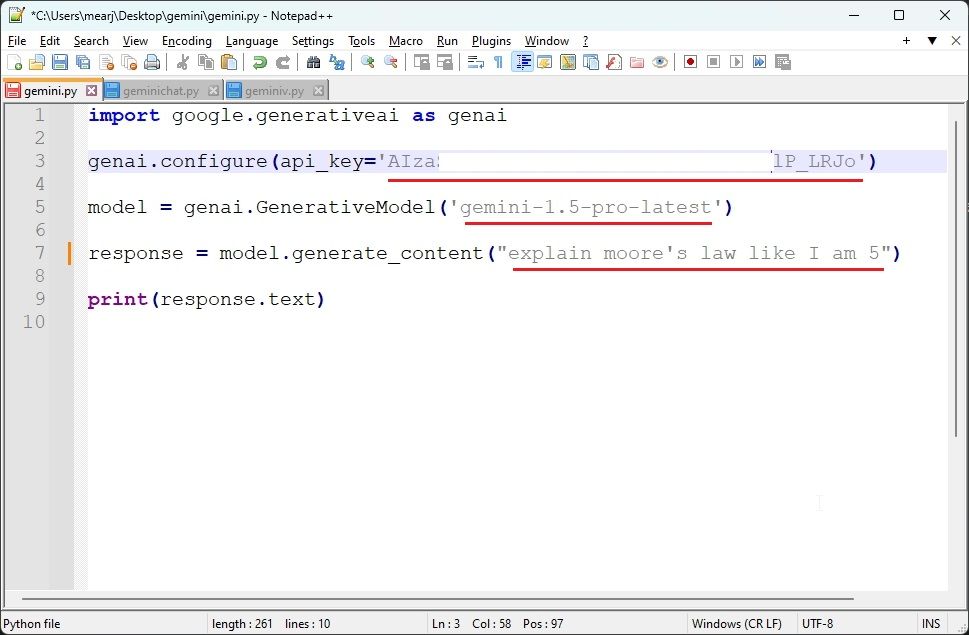
import google.generativeai as genai
genai.configure(api_key='XXXXXXXXXXXXXXXXXXXX')
model = genai.GenerativeModel('gemini-1.5-pro-latest')
response = model.generate_content("explain moore's law like I am 5")
print(response.text)
- Here, I have defined the model as
gemini-1.5-pro-latestand used my own API key. In the next line, you can set your question.

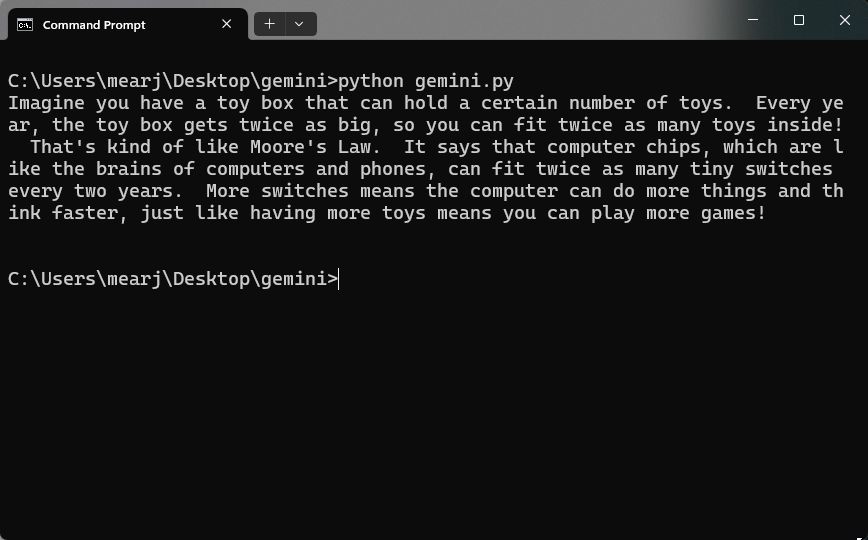
- Now, save the file with
.pyextension and run the file in your Terminal. As you can see, the Gemini 1.5 Pro properly explains the concept just like I asked it to do.

- Since Gemini 1.5 Pro is a multimodal model, you can also pass an image with the below code to check its vision capability.
import google.generativeai as genai
import PIL.Image
img = PIL.Image.open("image.png")
genai.configure(api_key='XXXXXXXXXXXXXXXXXXX')
model = genai.GenerativeModel('gemini-1.5-pro-latest')
response = model.generate_content(["what do you see in this image", img])
print(response.text)
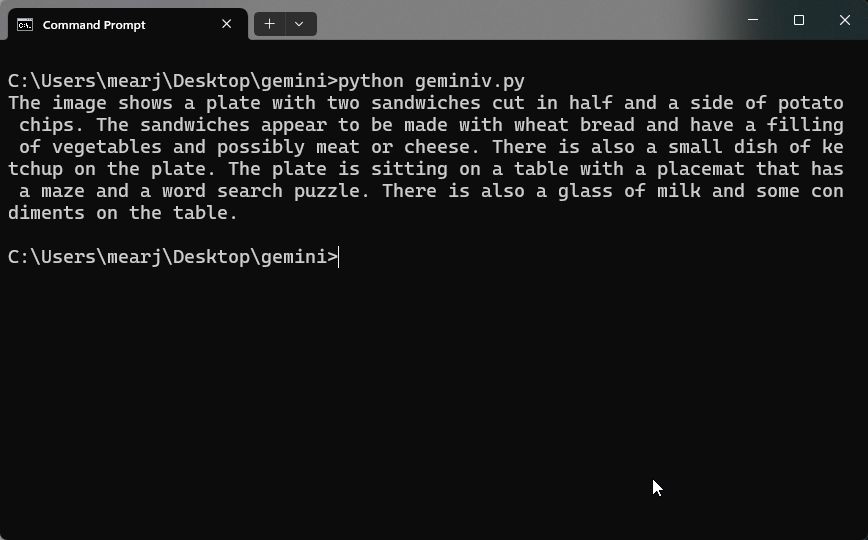
- Here, I am pointing to a local “image.png” file which is in the same directory as the Python file, and asking the question below.
gemini-1.5-pro-latestsupports text and image input in one single model.




- Now, simply run the code, and voila! It will analyze the image and output the result. I found it quite accurate when dealing with images.
Well, that is how you can access the API key for Gemini 1.5 Pro and test it with Python. By the way, Google has not published detailed documentation for the Gemini 1.5 Pro model. When Google updates its resources, we will add more coding examples in this article. Anyway, that is all from us. If you are facing any issues, let us know in the comment section below.




















