Are you running low on space on your Linux machine, but have no clue what keeps eating away at your precious storage? Duplicate files could be a major reason why you are facing low storage issues. Worry no more, as we will discuss some amazing tools to find and remove duplicate files in Linux in this article. These can help you to optimize your storage and improve the performance of your system.
Command Line Tools to Remove Duplicate Files in Linux
1. Using the fdupes command
Written in C language, the fdupes command is a free and open-source command line tool to find and delete duplicate files on your Linux file system. With fdupes, you can search for duplicates based on various parameters such as file names, MD5 hash, file size, etc. To install fdupes on your Linux system, use the following command as per your Linux distribution:
- For Debian-based systems:
sudo apt-get install fdupes- For RHEL/Cent-OS-based systems:
sudo yum install epel-release
sudo yum install fdupes- For Arch-based systems:
sudo pacman -S fdupesNow that you have installed fdupes on your system, let’s move on to its syntax and options:
fdupes <options> <path_to_search_in>Some of the common options to pair with fdupes command are:
| Options | Description |
|---|---|
| -r | Traverse through all the subdirectories present in the parent directory |
| -s | Follow directories linked with symbolic links |
| -A | Exclude hidden files from consideration |
| -m | Summarise the duplicate files comparison |
| -d | Prompts users for files to preserve while deleting all other files |
Let’s say, you want to search for duplicate files and delete them in the ~/Documents/test/testing directory, use this command:
fdupes -rd ~/Documents/test/testing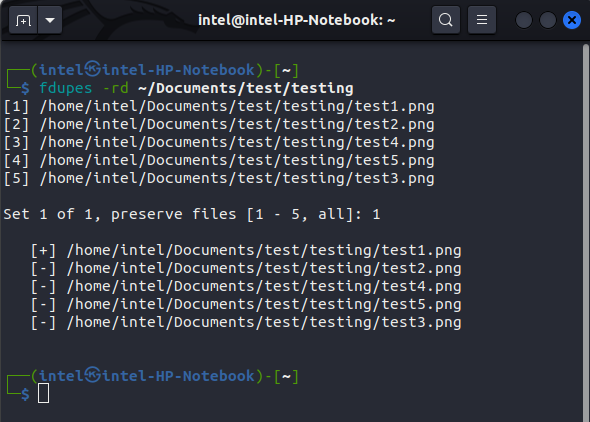
It will then prompt you for the set numbers to preserve; type the set numbers that you don’t want to be deleted. Other files except these will be deleted. The preserved files will be indicated by the “[+]” symbol in the front, whereas the ‘[-]’ symbol denotes the deleted sets of files.
2. Using Rdfind Command
The rdfind command, which stands for “Redundant Data Find,” is a free and open-source command line tool used to remove duplicate files in Linux. It uses a “Ranking Algorithm” to sort the files based on their inodes before reading the disk to compare files, making it way faster than any other tool. Use the following command to install rdfind as per your distro:
- For Debian-based Linux systems:
sudo apt install rdfind- For Fedora-based Linux systems:
sudo dnf install rdfind- For Arch-based Linux systems:
sudo pacman -S rdfindThe syntax to use rdfind is pretty easy:
rdfind <options> <directory_or_file_1> <directory_or_file_2>Some of the common options to pair with the rdfind command are:
| Options | Description |
|---|---|
| -ignoreempty | Ignores empty files while searching for duplicate files |
| -makesymlinks/-makehardlinks | Replaces duplicate files with symbolic/hard links respectively |
| -deleteduplicates | Deletes duplicate files |
| -removeidentinode | Removes items that have identical inode and device ID |
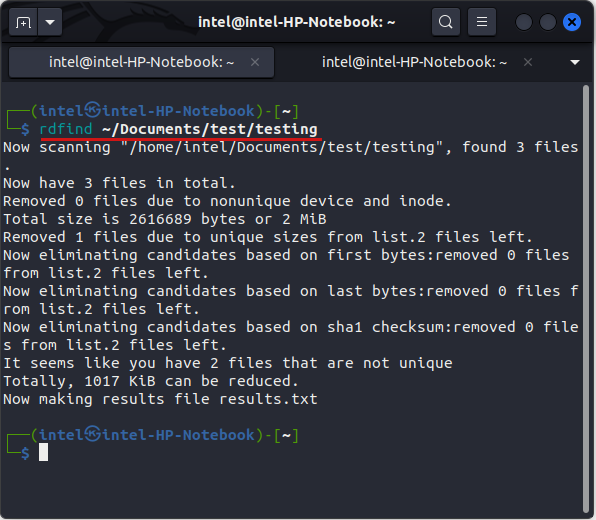
Let us now see how to use the rdfind command to find and delete duplicate files on Linux. Say you want to find all duplicate files in the directory ~/Documents/test/testing, use this command:
rdfind ~/Documents/test/testingOnce you execute the command, it will start scanning for duplicate files and storing their details in an autogenerated file called “results.txt” on your Linux machine.
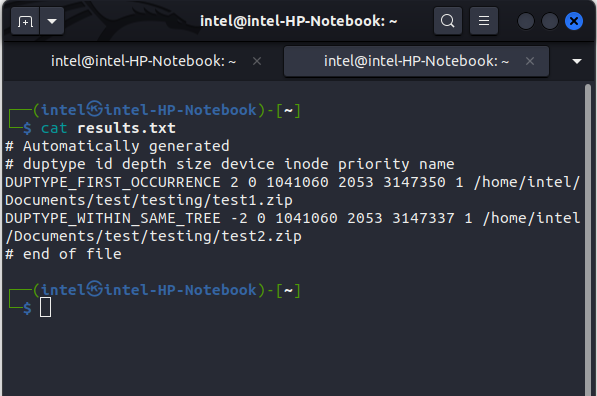
You can view the contents of the results.txt file using the cat command in Linux as follows:
To delete the duplicates found by the rdfind command, simply add the -deleteduplicates flag, like:
rdfind -deleteduplicates true ~/Documents/test/Instead, if you want to replace the duplicate files with hard links, use this command:
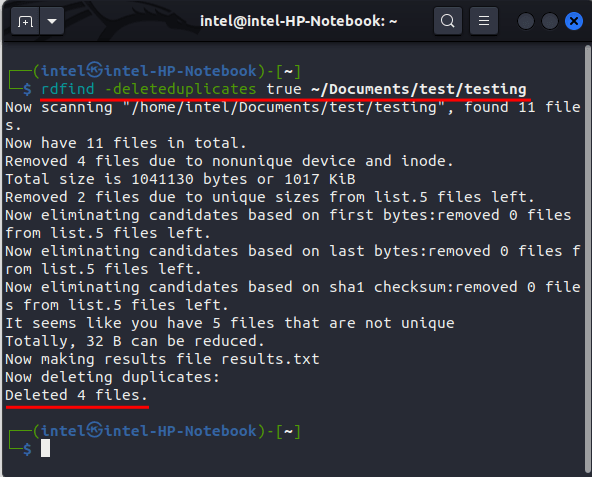
rdfind -makehardlinks true ~/Documents/test/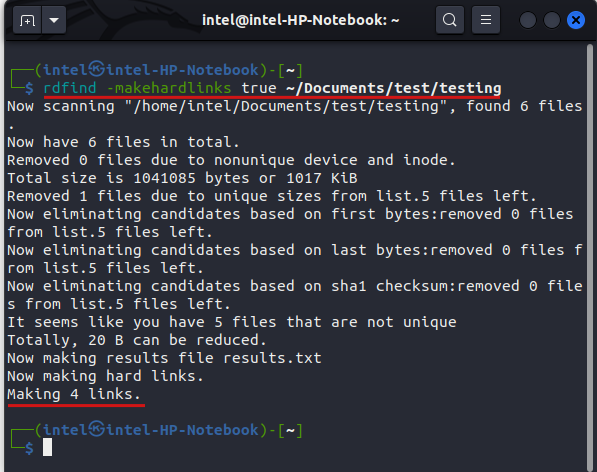
GUI Tool to Find and Remove Duplicate Files in Linux
The Graphical User Interface (GUI) tools provide a very easy-to-use and user-friendly approach to manage duplicate files in Linux. With a few clicks, you can find and delete duplicate files on your Linux file system, thereby, freeing up memory and enhancing your system speed.
The FSlint is both a GUI and a command-line-based tool catered to beginners and advanced users alike. With a few clicks, you can identify and eliminate duplicates, freeing up valuable storage space on your system. Follow these steps to install FSlint on any Linux distro:
Step 1: Install snap Package Manager
- For Debian-based systems:
sudo apt update && sudo apt install snapd- For Cent OS or RHEL-based systems:
sudo yum install snapd
sudo systemctl enable --now snapd.socket
sudo ln -s /var/lib/snapd/snap /snap- For Arch-based systems:
sudo pacman -S snapd
sudo systemctl enable --now snapd.socket
sudo ln -s /var/lib/snapd/snap /snapStep 2: Install FSlint Janitor with Snap
sudo snap install fslint-unofficialTo find and delete duplicates using FSlint, follow these steps:
- Launch FSlint Janitor from the applications menu.
- Click on the “+Add” button at the top left corner.
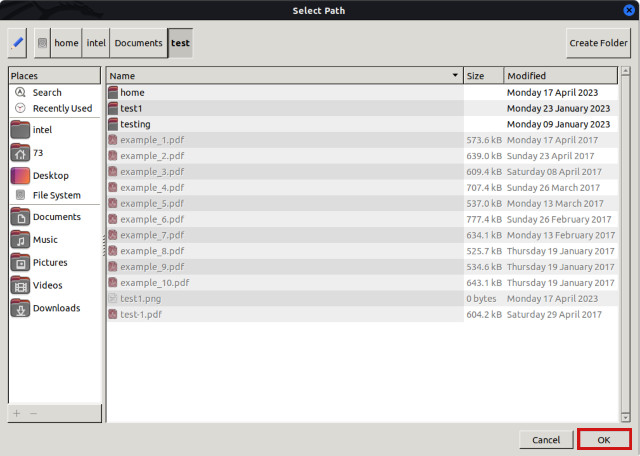
- Now, select the directory where you want to filter out the duplicates and click the “OK” button at the bottom right corner.
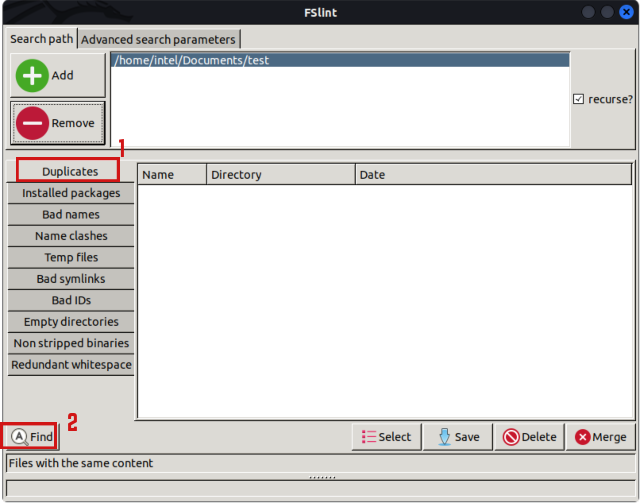
- Select the “Duplicates” option from the left-hand pane and click the “Find” button.
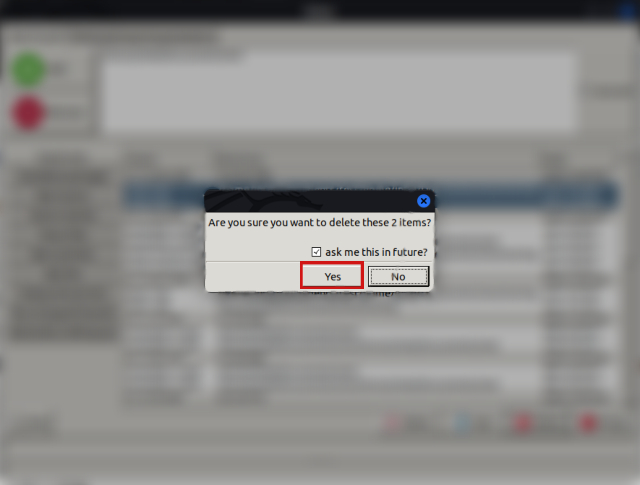
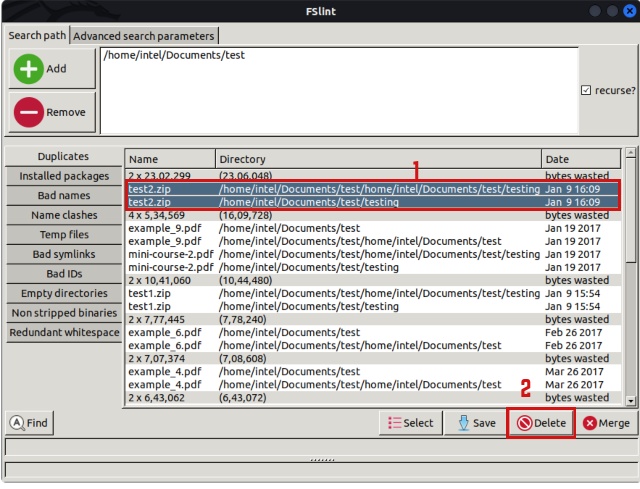
- The central pane will now display the duplicate files along with the memory occupied by them. Hold down the “CTRL” button on the keyboard while clicking on the file names you want to delete to select the files. When done, click the “Delete” button.
- Then select “Yes” on the confirmation pop-up window to delete the duplicate files.