
Every now and then, we get an image from a book excerpt or a content-heavy PDF that we want to edit or search. Then there are times, we have to extract tables from images to edit and add them to Microsoft Excel or a CSV file. In such cases, we need OCR software that can accurately recognize the character and convert them into text. It saves you a lot of time and hassle from manually typing the whole document. So to make things easier for you, we have compiled a list of the best OCR software (free and paid) that can convert images and PDFs into text with near-perfect accuracy. On that note, let’s go ahead and find the best OCR software, suitable for your needs.
Best OCR Software (2022)
Here, we have added the 8 best OCR software, both free and paid for general users and businesses. You can expand the table below to find all the OCR software in one place.
1. Tesseract
Tesseract is one of the best OCR software that is free and open-source. It’s developed by Google and has one of the best engines to recognize texts from PDFs and images. I have been personally using this OCR software to convert extracts from books, archives, PDFs, and more. The best part is that it can detect characters even from old books where the font size is too small and the text is almost illegible. It restores the font type and size according to the original text without much error.

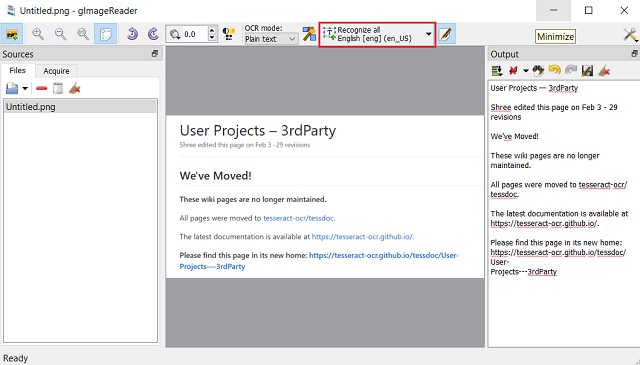
There are many GUI clients built on the Tesseract project. If you are a Windows user then gImageReader is the best OCR software that you can use. Linux users have OCRFeeder and macOS users can use PDF OCR X. And if you want to convert PDFs and images into text through a website then OCR.Space (website) is the one built on Tesseract. Not to mention, Tesseract supports over 100 languages including global and regional languages. So to sum up, if you want the best free OCR software, look no further than Tesseract.
Pros
- Free and open-source
- Quite powerful and accurate
- Supports over 100 languages
- Can detect handwritten and illegible documents
- Quite lightweight
Cons
- Not for business users
Pricing: Free
Download: Windows (Free), macOS (Free), Linux (Free), Web Browser (Free), Command Line (Free)
2. Sejda
For users who want to quickly extract text from PDFs and images, I will strongly recommend Sejda. It’s a free OCR software that is available in the browser and also offers a desktop client for Windows, macOS, and Linux. For casual users, I will suggest using its website since it’s free. Only paid users can download the desktop client. Anyway, talking about the features, its PDF editor is one of the easiest and most straightforward tools. You can edit PDFs up to 50MB in size under the free version.

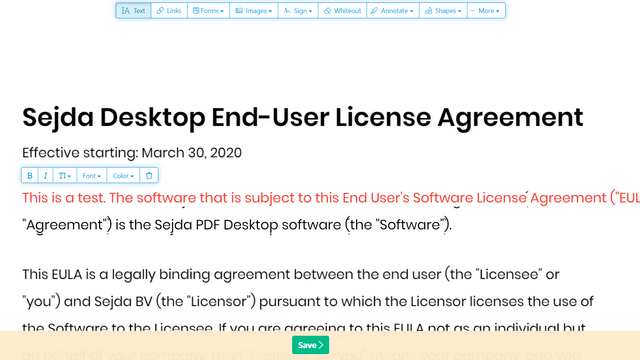
If you have got a screenshot or an excerpt from a book, Sejda can convert the PDF or image in no time. It supports multiple image formats such as JPEG, PNG, TIFF, and more. What I particularly like about Sejda is that it offers an accurate inspection feature where you can find out where the software thinks there might need a manual correction. You can export the text in a searchable PDF document and also in a plain text file.
The only con is that it only allows 3 tasks in an hour for free users, but I think it’s a fair limitation. We have written a detailed guide on how to edit PDF on Windows 10 for free so go through that for detailed steps. To conclude, Sejda ranks among the best free OCR software and you should definitely give it a try.
Pros
- Quick and easy OCR
- Free for the most part
- No watermark
- Pretty accurate
- Strict privacy policy
Cons
- 3 tasks in an hour for free users
- 50MB document limitation
Pricing: Free, Paid plan starts at $7.5 per month
Platforms: Windows, macOS, Linux, Web Browser
Download: Website
3. Microsoft Word / Excel / OneNote
If you are a Microsoft Office user then you don’t need to download a separate OCR software to convert PDFs and images into texts. Microsoft has added a powerful OCR engine into its software and that includes Microsoft Word, Excel, and OneNote. On Microsoft Word, you just need to open the PDF file using Microsoft Word and it will automatically convert the PDF to an editable Word file. How amazing is that? In case, you have got an image then add it to Word and save it as a PDF. Then open the PDF file using Word and there you have it! It even tries to keep the formatting and colors with near-perfect accuracy.
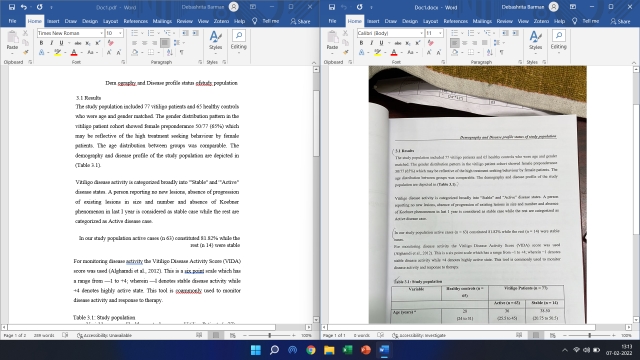
As for Excel, it comes in handy if you got lots of tables in an image. Look, I have tried lots of OCR software to extract tables but none of them have worked as good as Excel. Just open Excel and move to Data -> Get Data -> From File -> From PDF. And that’s how you can seamlessly extract tables with correct rows and columns position, color coding, etc. It’s that easier to extract tables from PDFs and images. Note that, this feature is only available to Office 365 subscribers.

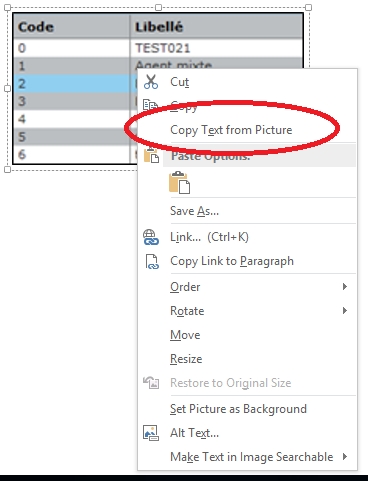
As for OneNote, simply add the image and right-click on it, and select “Copy Text from Picture“. You are done. To drive the point home, there is no better OCR software than Microsoft Office if you are already an Office user.
Pros
- Best OCR Software for Office users
- Supports images, PDFs
- Multiple language support
- Extract tables to Excel
- Add text directly to your notes
Cons
- Table extraction requires Office 365 subscription
- OCR not available on the web version of MS Office
Pricing: Paid plan starts at $6.99 per month
Platforms: Windows and macOS
Download: Website
4. Adobe Acrobat DC
As Adobe is the company that built PDF, it offers an unmatched OCR engine that can edit any PDF file you throw at it. It’s surely one of the powerful OCR engines in the industry and if you have large volumes of PDFs to edit, Adobe Acrobat DC is the one to get. You can convert both text-based and image-based PDF files right into its software with great accuracy. The best part about this software is that it retains the font of the original document using its Custom Font generation method.

Since Adobe has a huge repository of proprietary and designer fonts, it automatically matches the font style of the original document and then converts the PDF in that particular font. And in case, there is no font available then it generates a custom font using similar typography. This is the kind of feature that only Adobe can pull. So to put it straight, if you want to convert thousands of pages of scanned images in form of PDF files (like books) then Adobe Acrobat Pro DC is the best OCR software you can opt for.
Pros
- Accurate detection of characters
- Adds text to invisible characters
- Large support of fonts
- Uses proprietary typography
Cons
- Expensive for general users
Pricing: Free Trial for 7 days, Paid plan starts at $14.99/month
Platforms: Windows and macOS
Download: Website
5. ABBYY FlexiCapture
If you run a business then perhaps there is no better OCR software than ABBYY FlexiCapture. It’s a feature-packed software that supports over 200 languages and brings intelligent document scanning, unparalleled in the industry. It uses AI, machine learning, and advanced recognition technologies to accurately detect characters from images and PDFs. Not just that, ABBYY FlexiCapture adds a seamless workflow with automation tools if you want to perform batch jobs, and convert complex content-heavy documents with tables, graphs, photos, and more.

ABBYY FlexiCapture also leverages its NLP (Natural Language Processing) for identification, and extraction of data from unstructured documents giving you a hassle-free editable document that can be imported anywhere you want. One thing is for sure, if you are going to use ABBYY FlexiCapture then the need for manual processing will be reduced significantly. So if you are looking for the best OCR software for enterprises, give a serious look at ABBYY FlexiCapture.
Pros
- Features packed to the brim
- Best for business users
- Uses AI, ML and NLP for OCR
- Supports Automation
- Batch processing
- Support for over 200 languages
Cons
- Not for general users
Pricing: Free Trial for 30 days, Paid plan starts at $29.99/month
Platforms: Windows and macOS
Download: Website
6. OmniPage Ultimate by Kofax
OmniPage Ultimate is a professional-grade software to convert your images (JPG and PNG), papers, and PDFs to digital files. If you have a large company and need a reliable OCR program then I would highly recommend OmniPage Ultimate by Kofax. However, for individuals, this software would be too expensive.
Coming to features, OmniPage can accurately digitize images and documents while making them both editable and searchable. It also supports a long list of image formats so no matter the file extension, you can easily convert it to whichever file format you want. In terms of features, I would say, it’s very close to ABBYY FlexiCapture.

Apart from that, OmniPage Ultimate uses its proprietary technology to detect the layout of images and automatically rotates the document in the correct orientation. Further, you can schedule large volumes of PDF files for batch processing using its automation tool.
Not to mention, it can detect more than 125 languages and can process images and documents accordingly. As for output file formats, it supports PDF, DOC, EXCL, PPT, CDR, HTML, ePUB, and more. Considering all the points, OmniPage Ultimate seems a solid OCR solution for enterprise users.
Pros
- Feature-rich OCR
- Supports over 125 languages
- Supports PDFs and multiple image formats
- Hassle-free automation and batch processing
- Export to mutliple formats
Cons
- Accuracy is lower than ABBYY
Pricing: Free trial for 15 days, Paid version at $149
Platform: Windows
Download: Website
7. Readiris
On the hunt for an extremely powerful OCR software that’s heavy on features, but doesn’t really take a whole lot of effort to get started with? Take a look at Readiris, as it just might be what you need. A professional-grade application, Readiris has an extensive feature set that’s largely identical to the previously discussed ABBYY FlexiCapture. From BMP to PNG, and from PCX to TIFF, Readiris supports quite a few image formats.
Other than that, PDF and DJVU files can be processed just as well. Images can be sourced from scanner devices, and the application also lets you set custom processing parameters to source files/images, such as smoothening and DPI adjustment, before analyzing them. Although Readiris can process lower resolution images just fine, the optimal resolution should be at least 300 dpi.

Once the analysis is done, Readiris determines text sections (or zones), and the text can be extracted from either specific zones or the entire file. The extracted text is editable and searchable and can be saved in numerous formats, such as PDF, DOCX, TXT, CSV, and HTM.
What’s more, Readiris Pro’s cloud saving feature lets you directly save your extracted text to different cloud storage services like Dropbox, OneDrive, Google Drive, and then some more. There are also a healthy number of text editing/processing features as well, and even barcodes can be scanned.
All in all, you should use Readiris if you want robust text extraction/editing features in a simple-to-use package, complete with extensive input/output format support. However, Readiris does falter a bit when it comes to processing documents with complex layouts like multiple columns, tables, etc.
Pros
- Great option for enterprises
- Robust feature set
- Supports a long list of files
- Accuracy is quite good
- Batch processing
Cons
- Hand-written text accuracy is low
Pricing: Free trial for 10 days, Paid version at $129
Platform: Windows and macOS
Download: Website
8. Amazon Textract
In 2019, Amazon launched its OCR software called Textract which is built on a machine learning model and has been trained using millions of documents. It can automatically detect printed text from images (JPG and PNG) and PDF files and can convert them digitally with near-perfect accuracy. While Textract is primarily available on a web browser, you can also download it and use the service through the command line.
Apart from that, Textract seems a pretty powerful OCR software as it can not only extract texts, but also tables, fields, numbers, and key values. I particularly love the table extraction from scanned images as it can make things much easier while editing the text. Textract stores the table data using a pre-defined schema where it extracts all the data in the form of rows and columns.

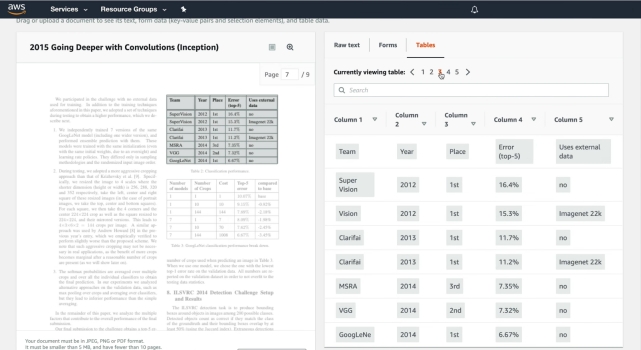
Having said all of that, Amazon Textract offers its service for both individuals and businesses. As a home user, you can sign up for AWS free tier account and use the service, but keep in mind, you can only convert 1000 pages in a month. Overall, Amazon Textract makes for a great OCR software and can be used by both general users and enterprises.
Pros
- Supports PDFs and multiple image formats
- Free for 3 months
- Supports table extraction
- Quite powerful at character recognition
Cons
- Not a desired option for general users
Pricing: Free for 1,000 pages per month for 3 months, Premium plan starts at $1.50 per 1000 pages
Platform: Web, Windows, macOS, Linux
Download: Website
BONUS: Google Keep and Google Docs
If you are someone who wants to convert images and PDFs on the fly, I will recommend Google Keep and Google Docs. Google Keep can extract texts from images within seconds and it supports regional languages too. The best part about this solution is how seamless the OCR process is and everything is available for free. Just add an image to Google Keep and click on the 3-dot menu and choose “Grab image text” and there you have it. Within seconds, all the text will be copied beneath the image. You can do this on the web and mobile app too. The only issue is that it doesn’t work well with tables but that is understandable.


Coming to Google Docs, if you want to convert PDFs then Google Docs lets you do it just like Microsoft Word. But unlike Word, it’s completely free. Just upload the PDF file to Google Drive and open it with Google Docs. It will automatically convert the PDF into an editable and searchable document in seconds. Whenever I have to convert images and PDFs to text, both these tools come in really handy and I think you should use them too.
Pros
- Quick and easy OCR software for general users
- Free to use
- Supports images and PDFs
- Mobile app support
- Available on almost all platforms
Cons
- Google Docs can’t convert PDFs of scanned images
Pricing: Free
Platform: Web, Windows, macOS, Linux, Android, iOS, iPadOS
Download: Google Keep (Web, Android, iOS), Google Docs (Web)
Find the Best OCR Software From Our List
So these are our picks for the best OCR software. We have added OCR software for both general users and enterprises. If you are a casual user then the free tools are enough and you don’t need to pay anything to edit PDFs and convert images to searchable text. In case, you have large swathes of archives books and complex PDFs then do go for the paid ones. Anyway, that is all from us. If you are looking for the best free word processors then head over to our linked article. And if you have any questions, let us know in the comments section below.


















