As a system admin on a Linux system, you might have to parse through a huge log file in Linux. It might seem a painstaking task, especially in the instances where you have to match patterns. Thankfully, grep command in Linux is a boon for such situations. If you are wondering what is grep command and how it works, below, we have prepared an easy guide to help you understand this useful Linux command.
What Is the grep Command in Linux
The grep command is a powerful command line tool in Linux used to search and filter out specific patterns or strings in a file, directory, or even in the output of other commands. You may be wondering about its unusual name; well it stands for “Global Regular Expression Print.” It was first introduced by Ken Thompson in 1973 for the Unix operating system. With its versatility and ease of use, the grep command is a must-have tool in every Linux user’s arsenal.
Generally, the grep command comes preinstalled on most Linux distros, but if you find it to be missing on your system, install it using the following commands:
- Install on Debian-based systems:
sudo apt install grep
- Install on Fedora-based systems:
sudo yum install grep
- Install on Arch-based systems:
sudo pacman -S grep
Linux Grep command: Syntax & Options
Using the grep command in Linux is pretty straightforward, thanks to its simple syntax along with the multiple options to play with. The syntax to use the grep command is:
grep <options> <pattern> <file_or_directory>
In the above syntax, replace the <pattern> with the pattern that you want to search, and for the <file> part, replace it with the file/directory you want to search in. And for the <options> part, there are different options you can work with including:
| Options | Descriptions |
|---|---|
-E | Interprets the <pattern> as regular expressions. |
-i | Searches for <pattern> and ignore the case. |
-v | Shows the lines that are not matching the <pattern> |
-c | Counts the number of matching lines. |
--color | Shows the results in colored output. |
How to Use the Grep Command in Linux
Using the grep command is easy, and it follows a simple syntax. All you need to do is provide the file name or directory you want to search for and the pattern you want to match. For the pattern, you can use the exact words or regular expressions. You must be wondering – what is “regular expression” here? Regular expressions are special strings that are interpreted in a different manner when used in specific areas. They get replaced with all the possible combinations matching the pattern.
Say, for example, you want to match email addresses, you can use the regex “(.+)\@(.+)\n“. Seems complicated? Let’s break down this:
(.+)matches any characters except new lines\@checks if the “@” symbol is present in the given sentence.
Now that you know what are regular expressions and how the grep command works, let’s now see how to use the grep command in Linux.
Search For Strings in Files with grep Command
The most common way to use grep is to search for specific strings in a file. The basic syntax to search with the grep command in files is:
grep <options <string_to_search> <file_name>
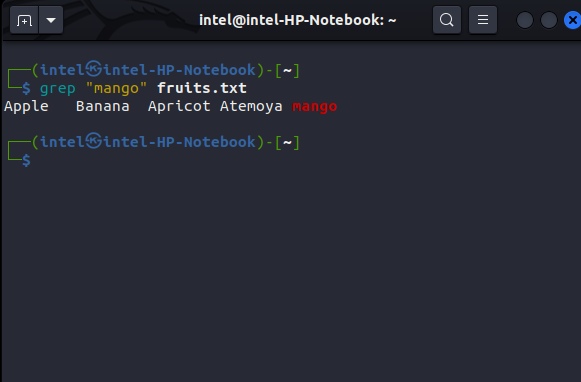
In the <string_to_search> part, you need to provide the exact string you want to search. For example, if you want to search for the string “mango” inside the file named fruits.txt, use this command:
grep "mango" fruits.txt
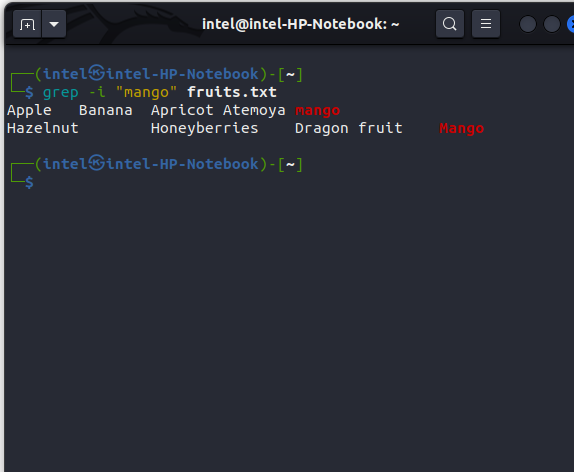
If you want to search while ignoring the case, then use the -i flag with the grep command for the above example:
grep -i "mango" fruits.txt
Search in Multiple Files with grep
With the grep command, you can not only search in a single file but also multiple files. This feature particularly becomes very handy when you need to go through multiple large files. The syntax to search for strings/patterns in multiple files with the grep command is:
grep <options> <string_to_search> <file_1> <file_2>
For example, if you want to search for the string “student”, inside the files “student1.txt” and “student2.txt,” use this command:
grep "John" student1.txt student2.txt
Search All Files in a Directory with grep
Suppose, you need to search for a string and you don’t remember the file name where it exists. You can obviously write all the filenames present in the directory, but instead, you can use simply use the “*” wildcard as shown:
grep <options> "pattern_to_search" *
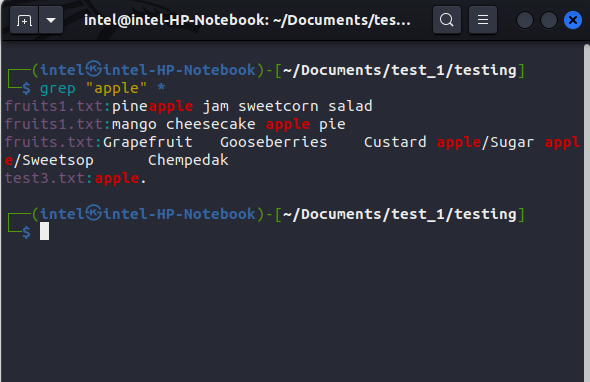
For example, if you want to search for the string “apple” in all files present in the directory, use this command:
grep "apple" *
If you want to search in specific file types only, use this syntax:
grep <options> "pattern_to_search" *.<file_extension>
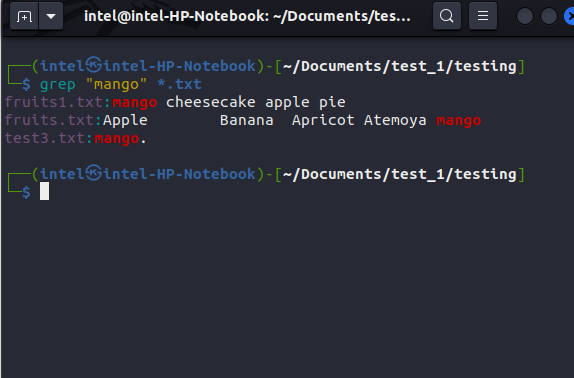
For example, if you want to search for the word “mango” only in .txt files, use this command:
grep "mango" *.txt
Using Regular Expression with grep
The main advantage of using the grep command over other tools/commands is the ability to process regular expressions to search for content. Simply include the -e flag with the grep command to search using regular expressions:
grep -e <pattern_to_search> <filename>
For example, if you want to filter out email IDs use this command:
grep -e "(.+)\@(.+)" emails.txt

Search for Multiple Keywords using grep Command
By now, you must be comfortable searching for some patterns or words using grep. But, what if you need to search for multiple words/patterns? Well, grep has got you covered for that too. To search for multiple words using the grep command, use this syntax:
grep "<query1>\|<query2>" filename
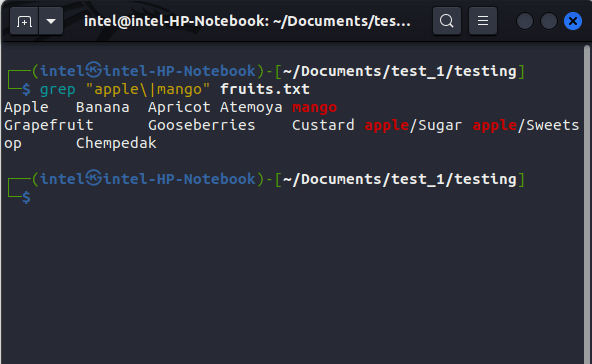
Here, the \| specifies grep to print the result if either of the two queries matches. For example, if you want to search for the words “apple” and “mango” in the file “fruits.txt”, use this command:
grep "apple\|mango" fruits.txt
Count Matching Results using grep Command
Sometimes, you may need to know the number of matching results. For this, you can use the -c flag with the grep command:
grep -c "pattern_to_search" filename
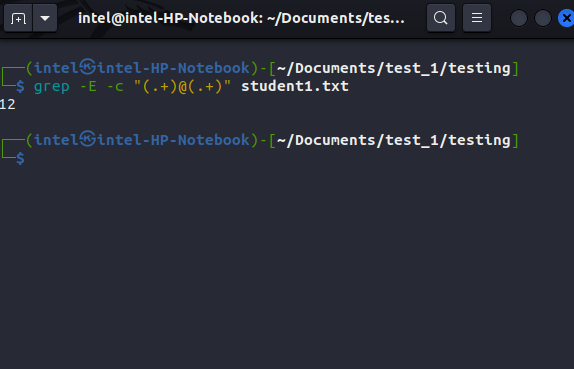
For example, if you need to see how many email IDs are there in the file student1.txt, use this command:
grep -E -c "(.+)@(.+)" student1.txt
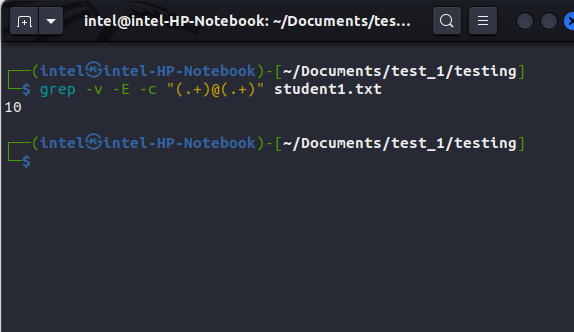
If you want to see the number of lines not matching the search query, simply add the -v flag along with -c:
grep -v -E -c "(.+)@(.+)" student1.txt
Using grep Command with Shell Pipes
The way shell pipes work in Linux is they send the output of one command to another command as input. The basic syntax to use shell pipes is:
first_command | second_command
With shell pipes, filtering out some command output with grep command becomes way easier, instead of constant scrolling and looking for something. To filter out a specific word or pattern from a specific command output, simply replace <first_command> in the above syntax with the command, and add the second command with grep command’s syntax. Here’s how it works:
first_command | grep <options> <pattern_to_look_for>
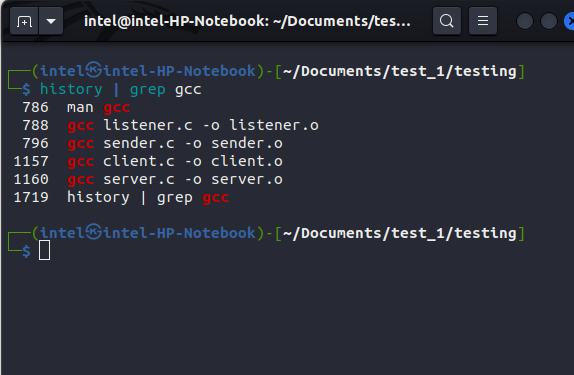
For example, if you want to see how many times the gcc command has been executed previously, you can use this command:
history | grep gcc
This will show only the results containing the word “gcc,” as shown in the picture below.
Using grep Command in Linux
The grep command is an essential tool for users who want to search for specific patterns or words in various files, directories, or even in other Linux command outputs. Once you have got hold of all the essential options and syntax, the grep command can help you to increase your productivity exponentially. While you are here, check out the new features in Ubuntu 23.04.
Grep Command in Linux FAQs
By default, grep works in a case-sensitive manner. But, if you need to search ignoring the case, use the -i flag.
Zgrep, a modified version of grep can be used to search in compressed files. The syntax to search in compressed files using the zgrep command is: zgrep "<pattern_to_search>" <compressed_file>






 Anshuman Jain
Anshuman Jain
