


Researchers at NVIDIA have developed a new AI capable of imitating the moves of a subject from a video to another person with a single input image. This technique is called video-to-video synthesis.
As the researchers say, Video-to-video synthesis converts an input semantic video like human poses or segmentation masks to an output photorealistic video. They have mentioned two major limitations in previous efforts for achieving this – data availability and limited generalization capability.
“To address the issue, we propose spatially-adaptive normalization, a conditional normalization layer that modulates the activations using input semantic layouts through a spatially adaptive, learned transformation and can effectively propagate the semantic information throughout the network.”, wrote the researchers.
The new model developed by researchers learns to create videos of subjects that were never seen before by using example images. This way, the need for a vast amount of data about the input is addressed.
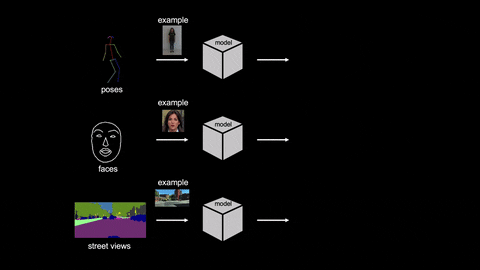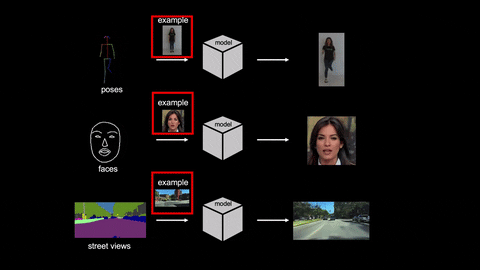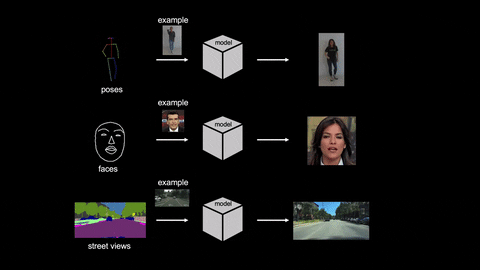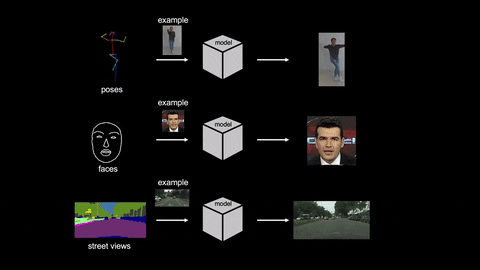

As you can see in the above GIF, the model managed to convert the actions to videos with a single input image. Cool, right?
The researchers conducted various experiments to test the efficiency of their AI model. This includes human-dancing videos, talking-head videos, and street-scene videos. Take a look at the sample video below.

According to the researchers, this is the first semantic image synthesis model capable of producing photorealistic outputs for distinct scenes including indoor, outdoor, landscape, and street scenes.
If you’re interested to know how this works, check the research paper published by NVIDIA’s researchers here. The project will be open-sourced on GitHub here soon. Until then, let us know your thoughts on NVIDIA’s efforts on this project in the comments.

