


- Google has launched its most capable Gemini 3.1 Pro model with top scores on Humanity's Last Exam and ARC-AGI-2.
- On SWE-Bench Verified, Gemini 3.1 Pro scored 80.6% while Anthropic's Claude Opus 4.6 achieved 80.8%.
- The new model is rolling out on Gemini, NotebookLM, Google AI Studio, and through Vertex API.
Google unveiled its most advanced Gemini 3.1 Pro AI model with record-breaking benchmark scores. It’s much stronger in multi-step reasoning and multimodal capabilities than the Gemini 3 Pro model. Google also says the new model is better at handling long, multi-step tasks. It’s rolling out in the Gemini app, NotebookLM, Google AI Studio, Antigravity, and through the Vertex API.
Gemini 3.1 Pro Scored Over 77% on ARC-AGI-2
First off, the new Gemini 3.1 Pro AI model scored 44.4% on the challenging Humanity’s Last Exam without any tool use, and 51.4% with search and coding tools. In the novel ARC-AGI-2 benchmark, Gemini 3.1 Pro scored a whopping 77.1%, even higher than Anthropic’s latest Claude Opus 4.6 which got 68.8%.

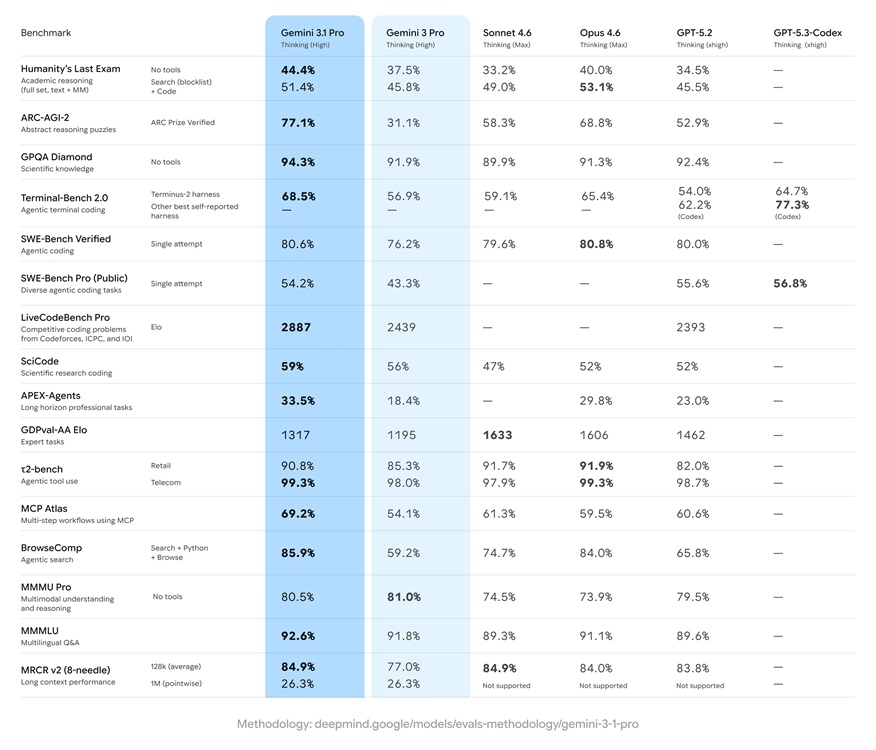
Next, in the GPQA Diamond benchmark, which tests scientific knowledge, Gemini 3.1 Pro scored 94.3% — higher than all competitors. As for SWE-Bench Verified which evaluates agentic coding, the Gemini 3.1 Pro AI model scored 80.6%, a notch below Claude Opus 4.6’s 80.8%. The new model has also gotten much better at following user instructions.
Google showcased a number of animated SVGs from Gemini 3.1 Pro and compared its output with Gemini 3 Pro. The difference is quite astounding when you see the vector illustration. Google says Gemini 3.1 Pro is currently in preview and the company will continue improving the model before making it generally available for everyone.
In December, OpenAI launched its ChatGPT 5.2 model to counter Gemini 3 Pro and recently unveiled GPT-5.3-Codex for improved agentic coding performance. Now that Gemini 3.1 Pro is out, OpenAI will have to release a much powerful model to outclass Google in the AI race.

