


- CNN in deep learning is a special type of neural network that can understand images and visual information.
- It works just like human vision: first it detects edges, lines and then recognizes faces and objects.
- CNNs (Convolutional Neural Networks) got popular in 2012 with the introduction of AlexNet, which identified images with human-level accuracy.
Have you ever wondered how Google Photos recognizes your face and stacks your photos together? That’s CNN (Convolutional Neural Network) at work which classifies images based on similar features. CNN is a type of neural network in the AI field that allows computer systems to process visual information with great accuracy. So to learn more about CNN in Deep Learning, follow our explainer below.
What is CNN in Deep Learning?
CNN or Convolutional Neural Network is a special type of neural network in deep learning that is designed to process grid-like data, particularly images. While there are different types of neural networks that can analyze images, they struggle to recognize patterns in images because they treat each pixel as an independent feature. Basically, it becomes computationally overwhelming for the system to analyze each pixel.

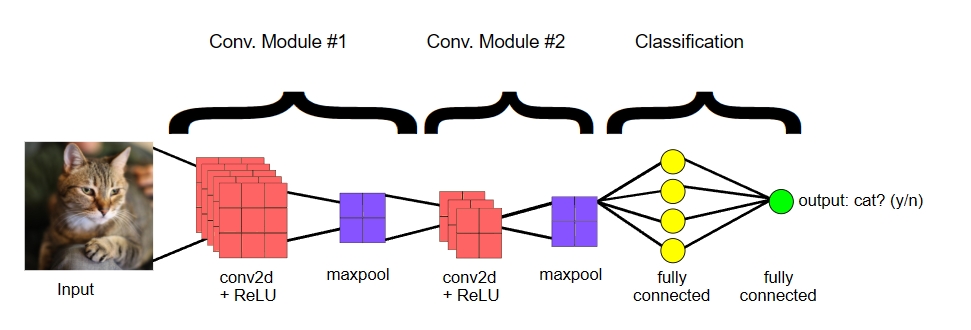
CNNs, on the other hand, can recognize patterns in visual data much more efficiently. CNN in deep learning work similar to how humans process images or any visual information. We don’t analyze every single pixel, instead, our brain identifies edges, shapes, textures, and gradually recognizes complete objects like faces, cars, or animals.
Basically, CNN in deep learning refers to this type of neural network that follows a hierarchical approach in identifying visual information.
How CNNs Actually Work?
Convolutional Neural Networks (CNNs) have a layered architecture where each layer extracts complex features from an image. First off, the Convolutional layer, which is the most important one, uses small filters to slide across the image. It looks for specific patterns in the image. It may detect basic details like horizontal lines, vertical lines, or edges.
As the network goes deeper, the filters start to recognize complex patterns like curves and textures. Gradually, the network recognizes the entire object. To give you an example, when you hold a small magnifying glass and move it across a painting, you look around to examine the painting. Similarly, the Convolutional layer slides across the image and performs mathematical operations to find whether certain features are present or not.
Now, the pooling layers take these extracted features and reduce the spatial dimensions of the data. It simply means that it only keeps the strongest signal from each region so that the network can efficiently process the data. Now, fully connected layers in CNNs take these extracted features to classify the image.
If the CNN is trained to recognize animals, you get “this image contains a dog” based on all the features extracted from previous layers. This is how the AI works to recognize objects in images.
The Origin Story of CNN
The development behind CNN is quite interesting. Yann LeCun is widely credited as the creator of modern CNNs, who introduced a network that could recognize handwritten digits in 1989. However, much before in 1980, Japanese computer scientist Kunihiko Fukushima introduced the “Neocognitron” which laid the groundwork of how layered networks could process visual information.


Fukushima’s Neocognitron was indeed way ahead of its time and introduced many key concepts like hierarchical feature detection used in CNNs. However, LeCun added backpropagation for training CNNs which allowed the network to learn automatically from data. In a way, LeCun popularized the use of CNN.
A major development happened in 2012 when Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton introduced a CNN called AlexNet which won the ImageNet competition by a significant margin, defeating all other traditional approaches. This showed that with enough data and computing power, CNNs can outperform traditional methods for vision analysis.
How CNNs are Trained?
To train a CNN, you need an enormous amount of labeled data. Basically, to classify images, you need millions of images labeled with the description of the image. The network now makes predictions, compares them to the correct answers and adjusts its parameters to improve accuracy and performance. This process is called backpropagation and it’s repeated millions of times until the network learns to recognize patterns from images.
The Future of CNNs
While CNN has had an enormous impact in the Artificial Intelligence (AI) field, new technologies like Vision Transformers (ViT) are showing better performance and accuracy. These are basically Transformer-based models, which uses sequences of patches to process images rather than using convolutional filters. Sure, ViTs are more accurate and powerful, but they also need more computing resources.
In that sense, CNNs are more efficient and can be used in edge devices like mobile phones where you have limited computational resources. In any case, CNN has significantly advanced the field of deep learning as it finally allowed computer systems to process and understand visual information.











