
Have you ever wondered how long it would take for an AI to learn and replicate your voice? Well, the answer to this question might come as a surprise as a new AI manages to mimic your voice after listening to it for a mere 5 seconds.
Yes, you read that right. Researchers at Google have developed a neural network-based system for text-to-speech (TTS) that manages to replicate the voice of speakers, including the ones that were never heard while training the AI of course.
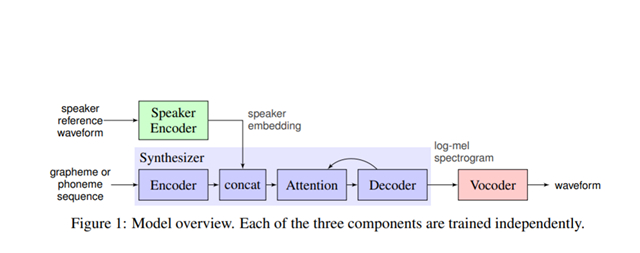
The proposed system consists of three major components namely a speaker encoder, a synthesizer, and a vocoder. The speaker encoder is trained on a dataset containing speeches of over a thousand people without transcripts. The synthesizer generates a “mel spectrogram” from the input text.
A vocoder network based on DeepMind’s WaveNet is implemented in the network to convert the mel spectrograms generated by the synthesizer to waveform samples. Take a look at the overall flow of the system in the below diagram.
The researchers tested this system to determine the naturalness of the generated synthesized speech. For this, they created an evaluation set containing 100 phrases that are never used before in the training set and tested with two different sets of seen and unseen speakers. The proposed model scored 4.0 Mean Opinion Score (MOS) with 95% confidence levels.
It is worth noting that the audio generated by their AI model for unseen speakers sounded as natural as the audio generated for seen speakers – the speakers whose voice has been used during the training phase.
If you’re interested to know how good the synthesized outputs are, listen to the below reference voice and synthesized outputs.
(Reference Audio)
(Synthesized Audio)
More samples are available here if you’re interested to explore more speech samples. To know more about how this system works behind the scenes, check out the research paper here and let us know your thoughts on it in the comments.